A while ago I added comments for my Jekyll base blog. Since then, I switched to zola. Its basically a Rust based "clone" of the static site generator (SSG) Hugo. Compared to Jekyll, it is a lot faster, and I found it to be a lot simpler. However, Zola has its own set of challenges. For instance, changing themes is nearly impossible and theme extension can get messy. That is the story for a future post. At some point I might consider creating my own SSG. Building a small one should be easy enough (and due to GitHub's Actions it could be used immediately).
Why did I move? Jekyll was basically the go-to SSG back when GitHub only supported it. And it always supported an outdated version. And Jekyll is generally pretty slow. And after some small update I could not get it to run on my machine in a reasonable amount of time (minutes is reasonable here). Searching for a new led me to Hugo, and then in turn to its Rust "clone" Zola. I tend to prefer applications written in Rust nowadays, but only slightly - due to the fact that I could contribute code.
Oh and, while migrating, I trashed the comment functionality - oops. Now its time to restore it back to its old (and pretty empty) glory.
Previously I used CGI. It's a bit archaic and cumbersome. So here's what we'll do:
- First, we'll transform it to a web service
- We'll switch from our custom (and now obsolete) GitHub client to a working one I don't have to maintain
- Our Javascript client needs to be re-added to the new Zola generated site
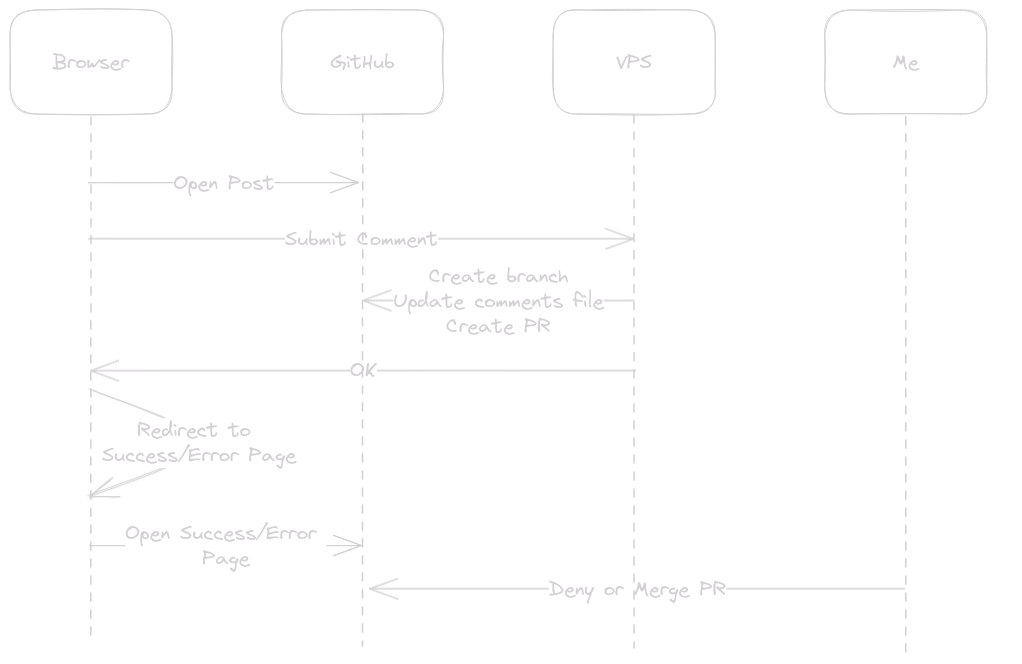
Here's a sequence diagram of how it is supposed to work:
🔗Our own Web Server
Now, first, we need to implement our own TCP stack... J/k we'll use hyper. We could use Axum but we won't be needing any full blown web server anytime soon.
Let's fire up a simple server at 127.0.0.0:3000:
use core::convert::Infallible;
use hyper::service::{make_service_fn, service_fn};
use hyper::{Body, Error, Request, Response, Server};
use std::net::SocketAddr;
/// This is the actual endpoint:
/// It should take a comment from a user by POST request and convert it to instructions on GitHub.
/// The result should be a branch which includes the comment. And a PR for the branch for easy review and merge-ability.
async fn post_comment_service(_req: Request<Body>)
-> Result<Response<Body>, Infallible> {
Ok(Response::new("Hello World".into()))
}
#[tokio::main]
pub async fn main() -> Result<(), Error> {
let addr = SocketAddr::from(([127, 0, 0, 1], 3000));
let post_comment_service =
make_service_fn(|_conn| async {
Ok::<_, Infallible>(service_fn(post_comment_service))
});
let server = Server::bind(&addr).serve(post_comment_service);
server.await
}
Simple enough.
🔗Choosing a GitHub Client for Rust
According to GitHub - there's no official client for Rust. But there are two third party clients. Octocat seems to be on the decline. I'm sorry if I misjudged here, I just compared the activity to the alternative Octocrab which has a lot more "everything". A quick check reveals it seems to be able to create branches, commits and PRs - everything we need. So we're using that, just a quick cargo add octocrab.
🔗Representing Comment Requests and Comment Data
Most of the post handling code is the same as before, for brevities sake I will only skim through here:
/// This is the request from a client
#[derive(Deserialize, Debug)]
pub struct Post {
path: String,
message: String,
name: String,
url: String,
}
/// This will be serialized into a comment file on GitHub
#[derive(Serialize, Debug)]
struct Comment<'a> {
id: &'a str,
message: &'a str,
name: &'a str,
url: &'a str,
date: u64,
}
So, let's modify our post_comment_service to actually do something. First we need to grab ourselves the content and then deserialize it to a Post:
let Ok(post_request) = hyper::body::to_bytes(body).await else {
[...]
};
let Ok(post): Result<Post, _> = serde_json::from_slice(&*post_request) else {
return Ok(Response::builder()
.status(StatusCode::BAD_REQUEST)
.body("Invalid JSON".into())
.unwrap());
};
Quick note: Using Axum, this would have been a lot shorter.
The next steps:
- Create a branch
- Add the comment to the correct
comments.yamlfile - Create a pull request
Creating a branch requires a commit SHA it is based on, so we grab that and create a branch of it:
let master_sha = match repo
.get_ref(&Reference::Branch("master".to_string()))
.await
.expect("Could not get master ref")
.object
{
Object::Commit { sha, .. } | Object::Tag { sha, .. } => sha,
_ => unreachable!(),
};
debug!("Creating branch {} from {}", branch_name, master_sha);
repo.create_ref(&Reference::Branch(branch_name.clone()), master_sha)
.await
.expect("Could not create branch");
Now, due to technical limitations (Zola can read a yaml file, but not a set of files) we need to have all comments of a blog in one file. This will be called comments.yaml as stated above.
A new comment should not just overwrite all other comments, so we first need to grab the file if it exists.
let content_items = match repo.get_content().path(&path).send().await {
Ok(content_items) => content_items,
Err(_) => {
info!("Assuming no comments present yet at {}", path);
ContentItems { items: Vec::new() }
}
};
// There can't be more than one file with the same name:
assert!(content_items.items.len() <= 1);
let content = content_items.items.iter().next();
Now lets create or append to the existing comment file:
let new_comment =
serde_yaml::to_string(&[&comment]).expect("Could not convert comment to yaml");
// Yes, this name is rubbish
let author = CommitAuthor {
name: "Comment0r".to_string(),
email: "none@example.com".to_string(),
};
if let Some(content) = content {
// GitHub API requires the SHA of the old file to update it
let (mut content, sha) = (content.decoded_content().unwrap(), content.sha.clone());
writeln!(&mut content, "{}", new_comment).expect("Could not add comment to file");
repo.update_file(
&path,
format!("Added comment from '{}'", comment.name),
content,
sha,
)
.branch(&branch_name)
.commiter(author)
.send()
.await
.expect("Could not update file");
} else {
debug!("Creating new file at {}", path);
repo.create_file(
&path,
format!("Added comment from '{}'", comment.name),
new_comment,
)
.branch(&branch_name)
.commiter(author)
.send()
.await
.expect("Could not create file");
}
I decided against parsing the existing file. It should be fine. If it's not, I can fix it manually, its a YAML file after all. Instead, just a "grab the existing content" and "append new comment" in YAML format, if nothing is there "create a new file" and "write the comment as initial content".
Last but not least, I don't want to manually merge or create pull requests, so let's do that as well:
oc.pulls(&config.owner, &config.repo)
.create(
format!("New comment from {}", comment.name),
branch_name,
"master",
)
.send()
.await
.expect("Could not create PR");
This will create a PR with the title "New comment from
Now, this service serves no purpose, if no-one ever calls it. That would be...
🔗The Client Part
I'll omit the html part for now, it's mostly a boring form with a name, an URL and a message field - and a submit button. The "interesting" part is the JavaScript client, that will do the following:
- Take the comment
- Send it to an endpoint
- Show the user a success or error page
Here is the first part:
const form = document.getElementById('commentForm');
form.addEventListener('submit', function (event) {
// Don't submit actually
event.preventDefault();
const formData = new FormData(form);
const commentData = {
name: formData.get('name'),
url: formData.get('url'),
message: formData.get('message'),
path: '{{ current_path | safe }}',
};
Don't get confused by the {{ ... }} stuff, that's part of the template engine Zola uses (Tera).
With the data firm in our grasp, onwards to step 2:
// Now post the comment to the service
fetch('{{ config.extra.api_url | safe }}/comment', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(commentData)
And finally step 3:
}).then(response => {
if (response.ok) {
form.reset();
window.location = "/pages/submitted";
} else {
window.location = "/pages/submission-failed";
}
}).catch(error => {
window.location = "/pages/submission-failed";
});
I also clear the form when the submit succeeded. Otherwise, returning to the page would keep the form content. On error, I let the content stay, maybe it was just a hiccup after all?
🔗Security
The service itself is pretty small. Due to Rust's nature, I consider buffer under/overflow attacks to be pretty unlikely. Not impossible mind you.
Rust could have some memory safety bug. Hyper uses some unsafe and could have a bug there. Same with tower which I will use below.
I pass much of the user entered data to Octocrab, which in turn relies on other libraries and interacts with GitHubs API. I expect their API to refuse any malformed requests, otherwise its their problem (unless..).
🔗Threat Model
The service will run on a trusted machine (due to access to a personal access token from GitHub). It is meant to run behind a reverse proxy, but should also work as a public service. It will not guarantee to work under a DOS attack, but it will guarantee not to let an remote attacker DOS the whole host system.
The main DOS vectors against the host system are:
- Sending large chunks of data in a post request which would then be sent to GitHub (clogging up up- and downstream)
- Sending many small requests which would result in a multiple of API calls to GitHub
🔗Changes Required by the Threat Model
First, lets limit the input our services receives to have some basic DOS protection:
let body = Limited::new(req.into_body(), 100 * 1024);
Let's also do some basic rate limiting:
let post_comment_service = make_service_fn(|_conn| async {
Ok::<_, Infallible>(RateLimit::new(
service_fn(post_comment_service),
Rate::new(1, Duration::from_secs(10)),
))
});
It would certainly be better to limit per IP. But the intention here was not to prevent DOS attacks to the service itself, just the host system.
🔗What's Next?
Obviously, the code could be improved - it was basically almost completely rewritten in about 2 days. This will have to wait for another time...
🔗Conclusion
It was a fun and sometimes tedious exercise. Hyper's API is "strange" - services return a Result<.., Infallible>. Why not just the real result. I guess I could read up on the reason, but its certainly hidden very well.
Octocrab is pretty decent. It's a bit cumbersome at times (i.e. send() for API that retrieves things). Authenication is really annoying and lacks documentation - but is easy enough once figured out.
I ran into an issue where I configured the wrong URL to access GitHub - I swear I saw it somewhere in the Octocrab repository.
This was made even worse by the API suddenly trying to deserialize incomplete JSON objects from GitHub (like cut off after 21 characters, without any reason why).
It took a fair bit longer than expected.
The parts I did not present:
- The cloudflare config to route the
apisub-domain to my VPS - My VPS' Apache2 config for a secure reverse proxy
- Getting a signed certificate
I hope you enjoyed this post of mine, feel free to comment. It should work now. If not, I'll just assume you're happy and live in blissful ignorance.